
Workshops will be held on 31 March 2026. Workshops will take place at TU Wien (Karlplatz 13, 1040 Vienna).
Workshops are for a limited number of participants to engage with an instructor(s) to learn the basics of a particular skill or concept.
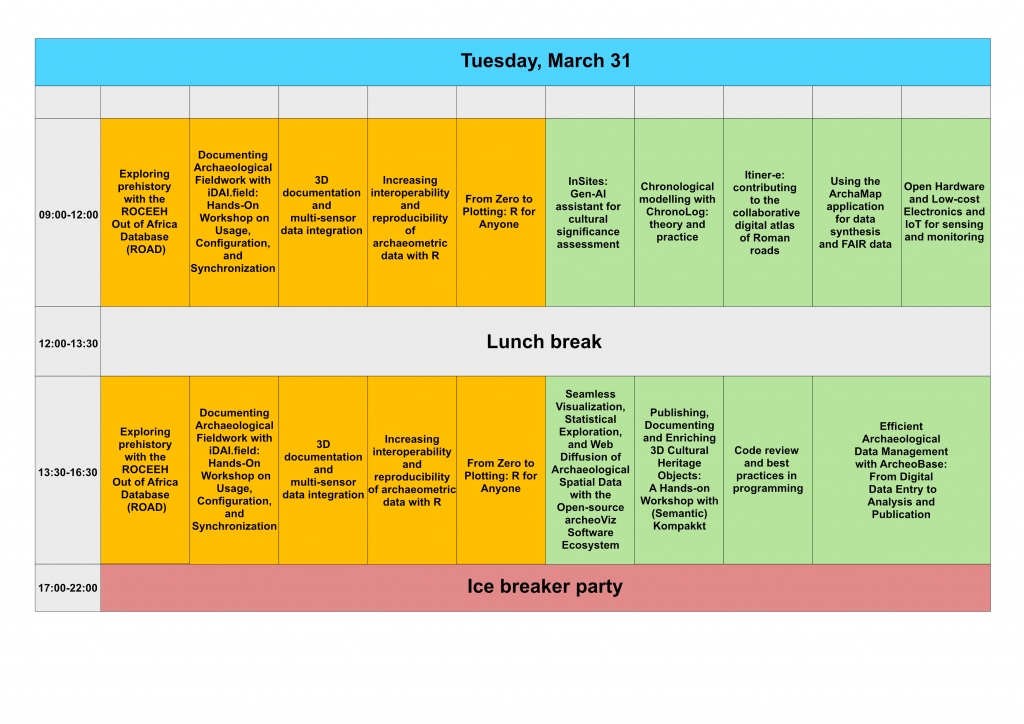
Full-day workshops
Exploring prehistory with the ROCEEH Out of Africa Database (ROAD)
Lead organizer: Christian Sommer, Jesper Borre Pedersen, Christine Hertler und Andrew Kandel
Lead organizer affiliation: ROCEEH Research Center (Heidelberg/Tübingen/Frankfurt)
Description: ROCEEH Out of Africa Database (ROAD) is a comprehensive, interdisciplinary resource for the study of human evolution (Kandel et al. 2023). Developed over the past 18 years by the ROCEEH research center (The Role of Culture in Early Expansions of Humans), ROAD integrates archaeological, anthropological, and paleoenvironmental data from Africa and Eurasia, spanning a period from 3,000,000 to 20,000 years before present.
ROAD currently contains information on over 28,000 assemblages and 2,600 localities, compiled from more than 6,300 publications in over 10 languages. It has become a critical tool for researchers conducting quantitative, computer-based analyses of human evolutionary history at multiple spatial and temporal scales (see: https://www.zotero.org/groups/5497463/roceeh/library).
This full-day workshop offers an introduction to the structure and core concepts behind ROAD. Participants will engage in hands-on exercises using browser-based user interfaces for streamlined data exploration. The workshop will also introduce the newly developed R package ‘roadDB‘, which enables seamless access to ROAD through one of the most widely used platforms for data analysis.
Finally, participants will have the opportunity to develop and run their own queries, with direct support from the ROCEEH team‚ playing the groundwork for incorporating ROAD into their own research.
References:
https://www.roceeh.uni-tuebingen.de/roadweb\
Kandel, A. W., Sommer, C., Kanaeva, Z., Bolus, M., Bruch, A. A., Groth, C., Haidle, M. N., Hertler, C., Heß, J., Malina, M., Märker, M., Hochschild, V., Mosbrugger, V., Schrenk, F., Conard, N. J. (2023). The ROCEEH Out of Africa Database (ROAD): A large-scale research database serves as an indispensable tool for human evolutionary studies. PLOS ONE, 18 (8), e0289513. https://doi.org/10.1371/journal.pone.0289513\”>https://doi.org/10.1371/journal.pone.0289513
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- Attendees are required to bring a laptop with a current web browser (preferably Firefox) and
- R Studio Desktop installed. While prior experience with R is helpful, it is not necessary‚ participants unfamiliar with the software are still welcome and will find the browser-based user interfaces intuitive and useful.
Maximum number of participants: 30
Documenting Archaeological Fieldwork with iDAI.field: Hands-On Workshop on Usage, Configuration, and Synchronization
Lead organizer: Fabian Riebschläger, Lisa Steinmann
Lead organizer affiliation: German Archaeological Institute
Description: iDAI.field (1) is free, open-source software for documenting archaeological fieldwork. It was developed and used by the German Archaeological Institute (2) since 2016, and has since 2023 been further advanced in the context of NFDI4Objects in collaboration with VZG (3). The iDAI.field ecosystem comprises FieldDesktop (offline-first data capture), Field Hub (internet synchronization), and Field Web (publication), enabling an end-to-end workflow from trench to dissemination. Its configurable data model, validation features, and open, standardized exchange formats support re-usability, comparability, and downstream archiving in line with FAIR principles.
Core capabilities
- A core data model for archaeological excavations that ensures basic comparability of all projects created with iDAI.field
- Flexibility to extend this data model, so that it can be adapted to the needs of different archaeological domains via a graphical configuration management. Built-in mechanisms for standardization and quality management to support comparability and reuse.
- Integrated image handling and geodata support.
- A customizable type management for e.g. find classification.
- A multilingual user interface (currently translations in 7 languages available) and multilingual data entry in any language .
- Inventory support with QR-code recognition.
- Full offline functionality with robust synchronization, both offline and online.
- Installation on all common desktop operating systems
- Strong emphasis on easy usability for quick on-boarding of field personell, such as students
- Import and export in standardized, open file formats
- Data and configuration access via REST API for integration with other systems or data analysis
What the workshop covers
This hands-on session introduces the essentials for using and tailoring iDAI.field with curated sample data. Short inputs alternate with practical exercises to help participants:
- Set up a project; understand the core data model, entities, relations, value lists, and type management.
- Configure an extended data model via graphical tools for different usage scenarios.
- Manage images and integrate geodata effectively.
- Apply quality-assurance and standardization options that enhance comparability and reuse.
- Import and export data with open formats.
- Collaborate safely using local backups and synchronization across multiple desktops
- Explore the REST API for lightweight interoperability with external systems
The workshop is designed to be directly transferable to active or planned field work without requiring programming skills
Target audience: Researchers at all career stages working in excavation, building archaeology, find processing or on surveys, who want offline, robust, shareable, and maintainable digital field documentation workflows.
1) https://github.com/dainst/idai-fieldn
3) https://www.gbv.de/informationen/Verbundzentrale\
Requirements: LCD projector, Wi-Fi, Sufficient power outlets for participants computers
Attendee requirements:
- No prior technical knowledge is required.
- All participants must have iDAI.field installed on their own computer ( https://field.idai.world/download ).
- A spreadsheet program should also be available (ideally LibreOffice or OpenOffice).
- Optional: for working with the REST API, it is recommended having R or Python installed and basic knowledge of one of the two programming languages.
Maximum number of participants: 20
3D documentation and multi-sensor data integration
Lead organizer: Ing. Bernhard Groiss1, Dr. Matthias Kucera2
Lead organizer affiliation: 1RIEGL LMS GmbH, 2University of Vienna
Description: 3D recording techniques became manifold during the last two decades, when laserscanning was first being used for archaeological purposes. Early work started to deal with terrestrial Laserscanning (TLS) for recording architecture, archaeological excavations and arcaheological landscapes. Airborne Laserscannig (ALS) is also applied for detecting new archaeological structures under vegetation cover. In addition, photogrammetric methods (Image based Modelling) became a complementary tool, which is used widely. To guarantee comparability of datasets standardized workflows for data acquisition, processing and filtering are crucial.
It is a great honour for Riegl LMS to organize a workshop aiming on the application of Laserscanning in cultural heritage and archaeological research. Long-term expertise in survey planning, processing, filtering, analysis and presentation of the data will be brought in by our trainers and partners. It is also a chance for us to learn more about current specific demands of archaeological research for more accurate implementation of features to our products. In this sense we are pleased to share our knowledge to pin down standardized methods for 3D recording of archaeological entities.
In the first part of the proposed workshop, we want to focus on TLS consisting of:
- Survey strategies
- Georeferncing including coordinate systems
- Monitoring
- Processing workflows
- Combination of TLS data and 3rd party results in RiSCAN PRO, Filtering of vegetation (LIS TreeAnalyzer, RiSCAN PRO plug in) and other filtering techniques
- Preparation of data for display and presentation
- Exchange with GIS-tools and software
Practical training will be carried out with Riegl LMS VZ-600i and the software RiSCAN PRO
In part 2 complementary datasets and their integration will be presented:
- Unmanned Aerial Laser scanning (ULS)
- survey strategies
- data processing and filtering
- Combination of TLS and ULS (ALS) datasets
- Bathymetric Laserscanning (BLS)
- technical introduction
- overview of the integration of photogrammetric datasets (Image based Modelling, Reality Capture)
- Integration of other sensor data (Infrared
- Interface to GIS-software
Attendees will benefit from:
- Presentation of newest TLS, ULS and BLS Laserscanners from Riegl LMS
- Practical training with VZ-600i
- Integration of different datasets (TLS, ULS, BLS
- Basic knowledge of the software RiSCAN PRO
- Design of specific survey strategies
- Presentation of results
- Analysis of the data
- Preparation of data for further spatio-temporal analysis in GIS and other tools
Requirements: LCD projector
Attendee requirements: Attendees can bring a PC to get temporal licensing for RiSCAN PRO during the workshop
Maximum number of participants: 20
Increasing interoperability and reproducibility of archaeometric data with R
Lead organizer: Thomas Rose1, Alexandra Rodler-Rörbo2
Lead organizer affiliation: 1Leibniz-Forschungsmuseum für Georessourcen/Deutsches Bergbau-Museum Bochum, Bochum, Germany; 2Austrian Archaeological Institute, Austrian Academy of Sciences, Vienna, Austria
Description:I ncreasing interoperability of datasets is pivotal for the implementation of the Open Science principles throughout the research data life cycle. As a step forward in archaeometry (the material-scientific analysis of usually inorganic archaeological materials) towards this goal, (https://www.lorentzcenter.nl/towards-an-archaeological-science-toolbox-in-r-astr.html) a workshop at the Lorentz Center in Leiden developed a common language for naming of datasets and data conventions in October 2025. The results were formalised in the R package ASTR (https://github.com/archaeothommy/ASTR\) and are described in its vignettes.
In addition to this common language, ASTR includes a collection of commonly used tools for data processing, visualisation, and interpretation in archaeometry to ease the transition from Excel and similar software towards scripting languages, increasing reproducibility and transparency. In this regard, ASTR is envisioned to complement existing and future packages for other specialisations in the archaeological sciences, ultimately creating an interoperable software ecosystem for the archaeological sciences and neighbouring fields.
This hackathon aims to continue the work started at the Lorentz Center while opening the project to the entire community. During the hackathon, the participants will be introduced to the common language and will be trained on how to integrate it in their functions. The workshop will focus on the development and refinements of the common language and participants can either work on functions and tools for ASTR or on adding support for the common language in other packages.
In addition, the workshop will offer the opportunity to meet the maintainers of ASTR and to discuss with them. ASTR is envisioned to be developed in a community effort, meaning that the maintainer team welcomes anyone who wants to join them on their quest towards interoperability and repeatability in archaeometry and beyond. Consequently, the next steps of the project will be discussed with all participants during the workshop.
Requirements: LCD projector, Wifi, extension cables and enough power sockets for the participants, Room with flexible layout to position tables for work group
Attendee requirements: Attendees should fulfil at least one of the following criteria:
- Comfortable in writing R functions or parts thereof (such as tests and documentation
- Familiarity in working with archaeometric/geochemical dataRecommended: GitHub Account (to directly contribute to the codebase)
- Experience in developing R packages
Maximum number of participants: 30
From Zero to Plotting: R for Anyone
Lead organizer: Petr Pajdla1, Peter Tkáč2,3, Vít Kozák3
Lead organizer affiliation: 1Czech Academy of Sciences, Institute of Archaeology, Brno; 2Czech Academy of Sciences, Institute of Botany; 3Masaryk University, Department of Archaeology and Museology
Description: “We will close your brackets and find all your missing commas!”
Intimidated by R? You’re not alone. Whether you’ve never written a line of code or struggled through previous attempts, this workshop is designed for you. We’ll demystify R and show you that data analysis and visualization aren’t just possible for archaeologists‚ they’re powerful tools that will transform how you work.
Over this hands-on session, we’ll guide you through the complete workflow: installing essential packages, reading, transforming and plotting data and ultimately understanding why R matters for reproducible research. We’ll use archaeological data, clean it up, organize it the “tidy” way, transform it to answer your questions, and create publication-ready plots.
We want you to leave the workshop with confidence to keep on coding!
What You’ll Learn
- Starting R and R Studio for the first time
- Installing packages
- Working in scripts and projects
- Reading your data with readr package
- Data cleaning and organizing them the tidy way with tidyr package
- Transforming and summarizing data with dplyr package
- Creating compelling visualizations in ggplot2 package
Who Should Apply
- Complete beginners with no coding experience
- People who’ve tried R before and found it frustrating
- Archaeologists wanting to improve data analysis and visualization skills
- Anyone curious about reproducible research workflows
- No prior programming experience necessary
- Just bring your laptop (with R (https://cran.rstudio.com/) and RStudio (https://posit.co/download/rstudio-desktop/)installed) and willingness to learn.
Format: Hands-on coding workshop with guided examples, archaeological datasets, and time to practice. We’ll troubleshoot together and emphasize learning over perfection
This workshop is co-organized by CAA Special Interest Group on Scientific Scripting Languages in Archaeology (SSLA), see https://sslarch.github.io/), (https://sslarch.github.io/)
Requirements: LCD projector, Wifi, If available: flip-chart/whiteboard if available + markers
Attendee requirements:
- Laptop
- R (https://cran.rstudio.com/)
- RStudio (https://posit.co/download/rstudio-desktop/) use this guide if needed: https://rstudio-education.github.io/hopr/starting.html
Maximum number of participants: 24
Half-day workshops
Open Hardware and Low-cost Electronics and IoT for sensing and monitoring heritage assets
Lead organizer: Juan Palomeque-Gonzalez
Lead organizer affiliation: IDEA, Madrid
Description: The rapid development of sensing technologies and analytical methods has made the use of IoT and smart devices increasingly valuable for monitoring environmental conditions that affect heritage assets, such as museum collections, archaeological sites, and historic buildings. Yet, the high cost of many commercial solutions often creates barriers for research teams with limited budgets. Furthermore, even affordable devices are frequently tied to proprietary service providers and closed cloud platforms, restricting flexibility and long-term sustainability.
This workshop introduces participants to open hardware and low-cost electronics for designing and building customised monitoring systems. We will begin by exploring Microcontroller Units (MCUs)‚ the core of IoT sensing devices‚ including widely used models such as the Raspberry Pi Pico, ESP32, ESP8266, and Arduino. Their differences, capabilities, and coding approaches will be compared to help participants select the most suitable option for their projects.
We will then examine a range of commonly used sensors and interface components, such as temperature and humidity sensors, motion and distance detectors, light sensors, switches, LEDs, and small displays. While it is not possible to cover the full spectrum of devices, the workshop will provide practical examples and general principles that can be applied across many sensor types.
Coding fundamentals will be introduced using open-source tools and two key programming languages: MicroPython, a lightweight Python implementation for microcontrollers, and Arduino C, a C++ variant originally developed for Arduino boards. Participants will learn how to connect sensors to MCUs, write simple programs, and build functioning prototypes.
In the final section, we will explore the networking capabilities of these devices, demonstrating how to gather, store, and analyse data locally or via open cloud-based solutions.
This will be a hands-on workshop, where attendees will not only gain theoretical knowledge but also actively construct and program simple IoT prototypes, leaving with both practical skills and a foundation for developing their own heritage monitoring projects.
Attendee requirements:
- Basic Python and computing background is important, but not essential
- A laptop to build the prototype (Windows preferred)
- Thonny (https://randomnerdtutorials.com/getting-started-thonny-micropython-python-ide-esp32-esp8266)
Maximum number of participants: 10-15
Efficient Archaeological Data Management with ArcheoBase: From Digital Data Entry to Analysis and Publication
Lead organizer: Dr Emmanuel Clivaz, Jean-Philippe Clivaz
Lead organizer affiliation: ArcheoBase
The session will be led exclusively by the founders of ArcheoBase, who will present the ArcheoBase platform.
Description:
Question Answered by this workshop
- How can we effectively overcome resource limitations (human, financial, and material) in archaeology to improve data collection and analysis?
- What are the best practices for developing and implementing standardized methods in archaeological data processing?
- How can we establish a unified, accessible online database to facilitate data sharing, knowledge transfer, and collaboration across institutions?
- How to enhance the accessibility of archaeological data and publications for both the public and researchers, ensuring cultural heritage preservation and visibility?
Summary
Participants will engage in an end-to-end journey of archaeological data handling, from initial data entry during excavation, through post-excavation analysis, to final publication, addressing critical questions using ArcheoBase
Workshop Outline
Excavation and Data Entry: Beginning in the field, participants will learn to record archaeological data efficiently using ArcheoBase‚ ArcheoEntry module, tailored for dynamic and adaptable data entry. This phase emphasizes the importance of capturing accurate data directly on-site, reducing redundancy, and minimizing errors that often arise from traditional paper-based methods. Through customizable digital forms, participants will capture data in a manner that is compatible with their own workflow and methodology, ensuring accuracy and consistency from the start. Participants will create digital forms based on their own paper templates, learn how to use the module to streamline teamwork on excavation sites, especially on large projects with multiple sectors and team members. They will experience live data entry directly from tablets or mobile devices, allowing everyone to capture information simultaneously and in real-time.
Post-Excavation Analysis: Moving to the post-excavation phase, the workshop will delve into data management and analytical techniques facilitated by ArcheoBase. Participants will utilize tools for organizing, validating, and analyzing data, including the integration of GIS and photogrammetry. Participants will learn how to link diverse data types, such as photographs, drawings, and forms, to create a comprehensive, integrated dataset. Through hands-on exercises, participants will see how ArcheoBase, capabilities support the automated generation of Harris matrices enhancing the interpretative depth of the data collected. Participants will also get an exclusive preview of ArcheoBase‚latest feature in development, a web-based, geolocalized drawing tool. This tool enables precise, GIS-integrated vector drawings directly in a browser.
The participants will export their data in xlsx format for comprehensive backups and further work with other software (R, python, etc.). They will also use Web Feature Services (WFS) that allows a direct synchronization between ArcheoBase and spatial analysis/mapping tools such as QGIS.
Data Publication and Accessibility: In the final phase, the workshop addresses the publication of archaeological data for both public access and academic use. Using ArcheoBase, ArcheoPublication and ArcheoView modules, participants will learn the process of preparing data for online publication, ensuring accessibility while safeguarding data integrity. ArcheoPublication also enables user to directly publish their work on their own institution‚ website via an IFrame, offering seamless integration and broader accessibility. This phase will highlight the platform‚ capacity to facilitate open data initiatives and public engagement, thus contributing to cultural heritage preservation.
Attendees will explore strategies to facilitate the handling of meta-projects, such as the swiss palafitte project, where members come from different institutions and collaborate on a centralized database for data entry and publication.
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- Bringing a laptop is optional
- Participants may connect to ArcheoBase on their own device if they wish, but this is not required, as the demonstration will be conducted live
Maximum number of participants: no limit
Code review and best practices in programming
Lead organizer: Matteo Tomasini
Lead organizer affiliation: University of Gothenburg, Sweden
Description: With the introduction of more and more digital tools in archaeology, most journals made it mandatory to publish software on a public repository such as Zenodo or Github, even when said software is not the central topic of a paper. However, during the process of peer review after submitting a paper, only a few journals requires of their reviewers to review a software. Additionally, in many cases the review does not follow a specific protocol to ensure that the code is running and functional. In other words, ensuring the correctness of code review is up to the reviewer’s time, capability and willingness.
On the contrary of code review performed in business software development settings – which aims at functionality as well as at uniforming a code base written by several individuals – the process of scientific code review aims at making sure that a code functions correctly, but it also aims at making it more readable by external individuals, and more usable in the future both as its own piece of software, or for further development. The consequence of lack of software review is that a lot of software becomes unavailable a few months after publication – either because it was not written nor assessed to ensure maintainability, or because the original developers left the building and nobody is able to pick up the obscure code.
A simple way to decrease the amount of published unusable software, is to perform code review on each piece of software that see the light of day on a journal. However, code review requires the collaboration of developers who are tasked with writing code better. This is why it is paramount to spread good practices in archaeological programming: these include code documentation (e.g. comments in the code), unit testing, proper software design and good stylistic writing. Learning these principles makes of us better software developers, but also contributes to making review of software easier on reviewers.
In this workshop, we will learn about software design principles and best practices in programming through a look at scientific code review. A short presentation will be followed by some hands-on work.
Requirements: LCD projector, Wi-Fi, Sufficient power outlets for participants computers, black/white board
Attendee requirements:
- laptop
- at least a little bit of experience in coding
- a Github profile would be useful, but not required
- Attendees are encouraged to find by themselves the code that they want to review during the hands-on part of the workshop. Being able to run code written in one of Python, R or NetLogo (or any other common language out there) will be necessary for the hands-on part: it would be beneficial to install all the necessary components for one or more of these languages before the workshop.
Maximum number of participants: 20
Using the ArchaMap application for data synthesis and FAIR data
Lead organizer: Robert J. Bischoff, Daniel J. Hruschka
Lead organizer affiliation: Arizona State University
Description: This workshop introduces ArchaMap, an application and database belonging to the CatMapper project, that facilitates synthetic research in archaeology by mapping and merging datasets through a transparent, reproducible process. ArchaMap is designed to assist users in creating and storing translations of complex categories (e.g., sites, ceramic types, periods) across datasets. Users can integrate diverse categories such as ceramic types, projectile points, time periods, culture areas, sites, or any other type of archaeological category. ArchaMap aligns with FAIR principles (Findable, Accessible, Interoperable, Reusable), ensuring data is easy to manage, share, and reuse across projects.
As an example, the cyberSW database in the Southwest US contains data on millions of ceramic sherds mapped to distinct ceramic types. ArchaMap provides tools to (1) to help users link ceramic types from new projects to the cyberSW ceramic types for new analyses, and (2) publicly share those new linkages for others to re-use.
Specifically, if a user has a spreadsheet of ceramic types from a new project, they can use ArchaMap’s translation tools to automatically find the best matches for existing ceramic types within the ArchaMap database leveraging a comprehensive set of alternate names and contextual information already included in the database. They can also limit their search to only those ceramic types currently used by the cyberSW databaseand those from a specific region or time period. These matches can then be verified for accuracy and modified as necessary. New categories can be created if a ceramic type does not currently exist within the database. After fully translating the new project’s ceramic types, the user can then upload the new project’s metadata and the translations of its ceramic types to ArchaMap categories
After storing the new translation, several ArchaMap tools permit users to find and re-use these translations between their dataset and the cyberSW dataset for future work. This process can be repeated to link multiple datasets. As new datasets are uploaded, each new translation increases the pool of alternate names available for matching, thereby making matching easier in the future. ArchaMap provides tools for easily finding metadata (including Citation and location or urll) on more than 2000 linked datasets, making their data more findable and accessible. By linking categories from one’s dataset to an ArchaMap category with a permanent URL and unique CMID (CatMapperID), it makes one’s data more findable and interoperable. By permanently storing the linkages between datasets, the data becomes more reusable
Another key aspect of ArchaMap is that it encodes multiple competing typologies. Researchers may choose to constrain matches by context or dataset to choose a particular typology that suits their needs or they can upload their own typology. The user is able to determine what constitutes a match and modify the translation to fit their needs. Disagreements in matches will be highlighted by the application and left for the user to moderate This workshop is suitable for researchers at any stage, with any type of data, from any region
Requirements: LCD projector, Wi-Fi
Attendee requirements: laptop or tablet
Maximum number of participants: 30
Itiner-e: contributing to the collaborative digital atlas of Roman roads
Lead organizer: Adam Pažout, Pau de Soto
Lead organizer affiliation: Universitat Autonoma de Barcelona, Spain
Description: Itiner-e: the digital atlas of ancient roads (https://itiner-e.org</a>) is an open online platform where it is possible to view, query, and download Roman road data. The digital atlas is currently populated by a dataset of some 300,000 km of roads covering all of Roman Empire that is a result of a joint effort of projects Viator-e: The Roads of the Western Roman Empire (PI Pau de Soto) and MINERVA: Understanding the centuries-long functioning of the Roman economy (PI Tom Brughmans, lead data collection Adam Pažout) with contribution from other collaborators from European and non-European institutions. While the current dataset appears impressive, it is far from complete and perfect. Many regions are poorly covered while in others spatial resolution and accuracy of the road data is low. Itiner-e was from the start intended to be an open platform, a scientific repository for researchers to share their research on Roman roads and contribute to the living atlas so that Itiner-e can become a comprehensive database and research tool for scholars and students and a dissemination tool for the public.
The aim of this workshop is to introduce the participants to the key concepts and functions of the platform, its data structure and how new data can be added and edited. In the first part of the workshop, we focus on the interface of the online platform, how to view, query, select, and download the Roman road data. The second part of the workshop is dedicated to the data structure, how the data can be created, prepared, and uploaded to the database. This is illustrated on practical exercises and real-world data. Finally, we would like to discuss with the participants methodological considerations in ancient road digitization, data standards, open data and FAIR principles in sharing research data on Itiner-e platform. With this workshop we hope to consolidate a growing community of scholars and students around Itiner-e so it can become living atlas of Roman roads showing the state-of-the-art of research on Roman road network. However, we would also like to invite researchers not working on Roman roads as we welcome insights from broader field of road archaeology and are ready to share and exchange our experiences from making Itiner-e.
Requirements: LCD projector, Wi-Fi, Electric plugs
Attendee requirements:
- laptop
- The practical part of the workshop involves work in GIS, so have a GIS software (such as QGIS which is free of charge https://qgis.org, or ArcGIS Pro) installed on your device.
- Basic GIS skills (vector layer creation and editing, editing of attribute data, export) are an advantage
Maximum number of participants: 20
Publishing, Documenting and Enriching 3D Cultural Heritage Objects: A Hands-on Workshop with (Semantic) Kompakkt
Lead organizer: Zoe Schubert1, Maria Sotomayor2, Prof. Dr. Øyvind Eide3
Lead organizer affiliation: 1TIB Leibniz Information Centre for Science and Technology and State Library Berlin; 2,3 University of Cologne
Description: 3D models are an essential component of archaeological and cultural heritage research, yet sustainable workflows for publishing, enriching, and documenting such data remain challenging. Researchers must navigate questions of interoperability, semantics, and annotation, and long-term accessibility while ensuring that their 3D data remain usable and citable in scholarly contexts. This half-day workshop introduces participants to open, standards-based methods for publishing and semantically enriching 3D cultural heritage objects, using the open-source platform Kompakkt as a central tool.
Kompakkt, originally developed at the University of Cologne, is an open-source infrastructure designed specifically for scholarly use and flexible presentation of 3D models. It supports viewing, annotating, and sharing 3D objects in a web-based environment. The platform also integrates with established cultural heritage data standards (e.g., the new IIIF 3D standard) and allows embedding in digital research environments. Its semantic extension, developed within the NFDI4Culture (https://nfdi4culture.de/) consortium at TIB in Hannover, provides an optional layer for linking 3D content with semantic web technologies, enabling persistent identifiers, interoperability, and machine-readable documentation. Together, these components exemplify how 3D data can be made FAIR (Findable, Accessible, Interoperable, Reusable) and sustainably reusable in research workflows.
The workshop will be led by an interdisciplinary team combining expertise from computer science, digital humanities, and digital archaeology. It is coordinated by the project lead and developer of (semantic) Kompakkt, together with a humanities scholar specialised in archaeology and a professor of digital humanities. This cross-disciplinary constellation ensures that both the technical and scholarly aspects of 3D publishing are addressed.
After a brief introduction to 3D publication standards, metadata practices, and IIIF-based interoperability, participants will receive a guided walkthrough of Kompakkt’s main features. The majority of the session will focus on hands-on work, allowing participants to use either their own 3D datasets (Kompakkt supports a wide range of formats: .laz, .las, .spz, .splat, .ply, .spx, .glb, .gltf, .obj, .stl) or provided example models to:
- Upload and publish 3D cultural heritage objects on Kompakkt
- Add and edit descriptive and structural metadata
- Annotate and enrich 3D models with research-relevant information
- Optionally, apply the semantic extension to link 3D content with Wikibase
Throughout the session, participants will discuss challenges, best practices, and scholarly use cases. By the end of the workshop, each participant will have created a personal Kompakkt profile and published at least one annotated and enriched 3D object. It’s also possible to publish through embedding on another website.
This workshop directly supports the CAA 2026 focus on open, transparent, and interoperable digital archaeology. It empowers researchers to adopt sustainable publication workflows and contributes to the broader discussion on FAIR data, semantic enrichment, and the long-term accessibility of 3D cultural heritage materials.
Expected outcomes
Participants will gain:
- A network of peers working on sustainable, interoperable 3D research infrastructures
- Practical experience publishing, annotating, and enriching 3D data using open-source tools
- Insight into IIIF-based and semantic approaches for 3D documentation
- A reusable workflow for FAIR-compliant 3D data management
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- Laptop for the hands-on session
- The workshop welcomes participants with an interest in 3D objects and their documentation. No prior experience with 3D software or coding is needed
Maximum number of participants: 20-25
Chronological modelling with ChronoLog: theory and practice
Lead organizer: Eythan Levy
Lead organizer affiliation: University of Zurich
Description: This workshop will present the foundations of ChronoLog, a free tool for building chronological models, testing their consistency, and computing tight, checkable, chronological estimates. These models consist of a network of entities (e.g. archaeological strata, ceramic periods, historical reigns) connected by a set of synchronisms. The tool allows users to modify the data in the model and assess on-the-fly the impact of these updates on the overall chronology. ChronoLog also allows users to add radiocarbon determinations to their models, and to convert the model automatically to an OxCal Bayesian radiocarbon model. This feature allows archaeologists with no knowledge of the OxCal specification language to build complex Bayesian models on their own, with just a few clicks of the mouse. ChronoLog is freely available for download at (https://chrono.ulb.be).
For more details on ChronoLog, a user manual is available on the ChronoLog website. For additional details, see the bibliography below, especially Levy et al. 2021 (Journal of Archaeological Science), and Levy et al., in press (Proceedings of CAA 2021).
The workshop will start with a general introduction to ChronoLog, its basic principles, and its main functionalities. The second part of the session will be devoted to practical modelling exercises, which users will do on their own laptops. In these exercises, users will first learn how to build chronological models by themselves, based on a wide set of archaeological and historical data. They will then explore how ChronoLog can serve as a useful tool for archaeological cross-dating. This part will also present the use ChronoLog as a front-end to OxCal for building Bayesian radiocarbon models. In the final part of the workshop, participants will be invited to present their own data sets, and will be assisted in the modelling of these datasets using ChronoLog
References
Levy, G. Geeraerts and F. Pluquet, in press. ‚ChronoLog: a Tool for Computer-assisted Chronological Modelling.‚Äù Proceedings of the 48th International Conference on Computer Applications and Quantitative Methods in Archaeology (CAA 2021-
Levy, I. Finkelstein, M.A.S. Martin and E. Piasetzky, 2022: The Date of Appearance of Philistine Pottery at Megiddo: A Computational Approach. Bulletin of the American Schools of Oriental Research 387, pp. 1-30-
Levy, E. Piasetzky, A. Fantalkin and I. Finkelstein, 2022: From Chronological Networks to Bayesian Models: ChronoLog as a Front-end to OxCal. Radiocarbon 64, pp. 101-134.
Levy, E. Piasetzky and A. Fantalkin, 2021: Archaeological Cross-dating: A Formalized Scheme. Archaeological and Anthropological Sciences 13, pp. 1-30.
Levy, G. Geeraerts, F. Pluquet, E. Piasetzky and A. Fantalkin, 2021: Chronological Networks in Archaeology: a Formalised Scheme.” Journal of Archaeological Science 127, pp. 1-27.
Geeraerts, E. Levy and F. Pluquet, 2017: Models and Algorithms for Chronology”, in S. Schewe, T. Schneider and J. Wijsen (eds), Proceedings of The 24th International Symposium on Temporal Representation and Reasoning (TIME 2017), Dagstuhl, pp. 13:1-13:18.
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- Laptop and Wifi connection
- ChronoLog app, available at https://chrono.ulb.be
- OxCal account at https://c14.arch.ox.ac.uk/oxcal/
Maximum number of participants: 20
Seamless Visualization, Statistical Exploration, and Web Diffusion of Archaeological Spatial Data with the Open-source archeoViz Software Ecosystem
Lead organizer: archeoViz maintenance team
Lead organizer affiliation: CNRS, CITERES lab., MASA+ consortium, France
Description:
Why coming?
You have spatialised archaeological data –from excavation archives or a total station–, and you want to explore it quickly and efficiently, make figures and perform statistical analyses for a report, publication or even a public presentation. Time is short and your budget is limited or equal to zero: what can you do?
How can the archeoViz ecosystem help you?
archeoViz is a stand-alone application designed for the visualization and statistical exploration of archaeological spatial data across multiple scales, from individual objects to excavation sites, landscapes, and entire regions. Tailored archeoViz instances can be deployed online to provide public access to specific datasets. Complementing this, the archeoViz Portalserves as a web application for discovering and browsing references to existing archeoVizinstances.
It is important to note that the archeoViz Portal is not a platform for data publication. While the publication of datasets is warmly encouraged, this should ideally be carried out using dedicated, specialized services such as Zenodo, Nakala, ADS, or tDAR.
Learn more about the archeoViz Ecosystem here:
https://analytics.huma-num.fr/archeoviz/home
https://archeoviz.hypotheses.org
Expected outputs of the workshop
Join the workshop with your spatialised dataset and, by the end of the day, and depending on your choice you might get: figures from your dataset from every angle, statistical analysis results, or even an online publication of your data and the creation of an interactive website to share with colleagues and local communities.
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- Laptop
- Participants should have R and Rstudio installed, No prior experience with R is required
- Bringing a personal dataset is not required but is very recommended: Participants will be asked to provide the workshop presenter with a brief description of their dataset (any type of spatialized archaeological data, such as objects localized within a site or sites localized within a region). For any questions about this requirement, please feel free to write to: archeoviz-maintainers@services.cnrs.fr
Maximum number of participants: 12
InSites: Significance Assessment through the Looking Glass of Gen-AI
Lead organizer: Dr. Yael Alef1, Yuval Shafriri2
Lead organizer affiliation: 1Technion, Israel Institute of Technology, Faculty of Architecture and Town Planning; 2YuValue – Edtech & Heritach consultant
Description: Articulating significance, which is crucial in value-based heritage management, is a complex interpretive task requiring the synthesis of diverse and fragmented evidence. While Gen-AI offers powerful processing capabilities, delegating this creative process to a machine raises critical ethical concerns.
In this workshop, inspired by Lewis Carroll’s novel Through the Looking Glass, we navigate this tension by positioning Gen-AI as a reflective partner. Using our InSites Human–AI agentic workflow, we will examine how transformer-based models complement Context-Based Significance Assessment (CBSA), as both fundamentally rely on deep contextual understanding. We move beyond the hype to ask: Can Gen-AI transparently read and analyze the site documentation so humans can better “read the site” and conserve it?
We will experiment with transforming site information (from excavation reports, etc.) into a structured assessment process, guiding users through “mini agents” steps in the InSites tool, each with optional training notes for learning purposes. We’ll move from detecting missing information and identifying contexts and values to drafting explainable significance statements. Beyond writing, we will experiment with multivocal narratives, knowledge graphs, and interactive views, ranging from standard timelines to novel participant-invented visualizations, that help gain new cultural insights and communicate them in new ways. The InSites workflow is grounded in three core Human–AI design principles: methodological alignment (embedding professional protocols), cognitive transparency and strict evidence grounding, which we will explore throughout the workshop sessions.
Workshop Program
- Theory & Demo: An introduction אם the CBSA methodology embedded in the system and how transformer models “mirror” it, followed by a live InSites demo.
- Hands-On Main Sessions:
- Write with InSites: Co-authoring a significance assessment for a site of the participants’ choice alongside the agent workflow, including the generation of visual artifacts and interactive dashboards.
- Read with InSites: Analyzing the generated assessments to detect hidden patterns.
- Ethics in Practice: Participants will apply the design principles to experiment with sketching a custom agent for their specific needs.
Workshop Takeaways
- A preliminary significance assessment report of the site and other generated artifacts.
- Hands-on experimentation with structured Human-AI collaboration workflows.
- Continued access to the InSites tool, website, and GitHub repository.
References
Alef, Y., & Shafriri, Y. (2023). Cultural Significance Assessment of Archaeological Sites for Heritage Management in the Digital Age: From Text of Spatial Networks of Meanings. https://doi.org/10.5281/ZENODO.8360843
European Archaeological Council. (2025). Assessing Archaeological Significance: Key Concepts (EAC Guidelines 9). European Archaeological Council. https://doi.org/10.5281/zenodo.10697000
GitHub Repository: https://github.com/InSites-Lab/Insites-CAA2026
Requirements: LCD projector, Wi-Fi
Attendee requirements:
- A Laptop and Wi-Fi.
- AI Access to a capable model (e.g., Gemini pro, ChatGPT Plus, DeepSeek etc.)
- Material to work with (recommended): Site documentation (pdf/word files, images, etc.) for personal case studies (we will also supply example site documents).
* We’ll be happy to advise in advance on AI access and suitable materials
Maximum number of participants: 25